flowchart LR
A[Estatística <br/> tradicional]--- B[Estatística descritiva]
A --- C[Estatística inferencial]
A --- D[Modelação estatística]
B --- E[Medidas de frequência <br/> absoluta ou relativa.]
B --- F[Medidas de tendência <br/> central e dispersão: <br/> e.g., média, desvio padrão.]
C --- G[Estimação]
C --- H[Testes de Hipótese]
D --- I[Regressão]
style A color:#980000, stroke:#333,stroke-width:4px
9 Introdução
Quando finalizar este capítulo, deverá ser capaz de:
9.1 A disciplina de estatística
A disciplina de estatística é a disciplina que estuda os métodos de recolha, organização, sumário e apresentação de dados, assim como os métodos de inferência e modelação desses mesmos dados.
Tradicionalmente, a estatística (frequentista) inclui três ramos (Figure 9.1):
estatística descritiva, que inclui as medidas de frequência, tendência central e dispersão, que descrevem a distribuição dos dados.
estatística inferencial, que tem como objetivo generalizar para a população as conclusões obtidas com base numa amostra, onde se incluem os testes de hipótese.
modelação estatística, que tem como objetivo criar modelos para fazer previsões da realidade com base nos dados existentes.
9.2 Variáveis e Dados
Variáveis
Uma variável é uma determinada característica que pode variar ou assumir diferentes valores.
Os investigadores desenham frequentemente estudos para testarem se alterações numa variável estão associadas a alterações numa outra variável de interesse. Por exemplo, se investigadores procurarem saber se uma nova terapêutica é mais eficaz do que outra terapêutica já existente no tratamento da hipertensão arterial, poderiam desenhar um ensaio clínico aleatorizado para testar esta hipótese: os participantes seriam aleatoriamente alocados a um de dois grupos, o grupo experimental, que receberia o novo fármaco, e o grupo de controlo, que receberia o fármaco convencional. Neste exemplo, o tipo de tratamento (i.e., novo tratamento vs. tratamento convencional) é a variável independente, enquanto que a diminuição da pressão arterial é a variável dependente (DV).
Dados
Os dados biomédicos têm características particulares por comparação com outros domínios do saber. Quaisquer dados de saúde podem ser considerados dados biomédicos, por exemplo, dados administrativos dos hospitais, dados de biomarcadores, dados biométricos (por exemplo, de smart watches) e dados de imagem. Os dados biomédicos podem ter múltiplas origens, desde os registos de saúde eletrónicos, registos clínicos, biobancos, os próprios pacientes ou mesmo a internet (por exemplo, é possível fazer estudos infodemiológicos com dados do Twitter).
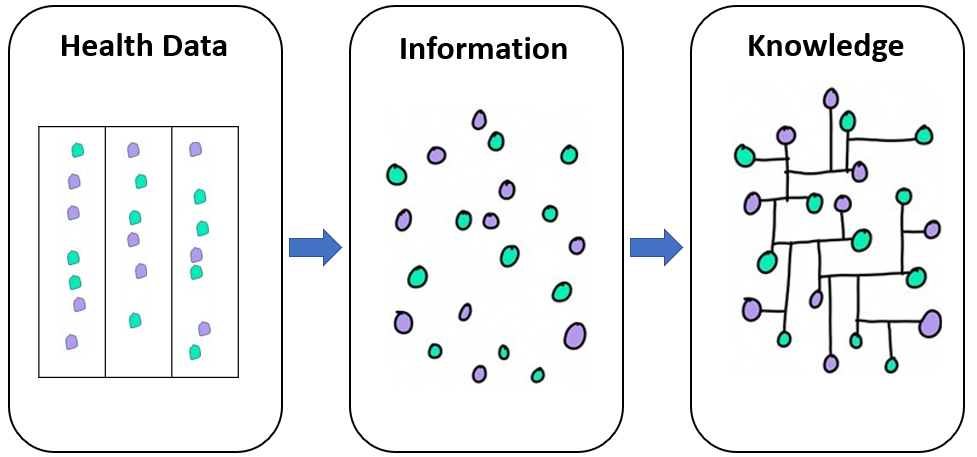
O processamento dos dados biomédicos gera informação, que se pode tornar conhecimento(Figure 9.2).
Os dados podem ser classificados em categóricos (também conhecidos como qualitativos) ou numéricos (também conhecidos como quantitativos) (Figure 9.3).
flowchart TB
A[Dados nas variáveis]---> B[Dados categóricos]
A[Dados nas variáveis]---> C[Dados numéricos]
B ---> E[Nominais<br>p.ex. tipo sanguíneo A, B, AB, O]
B ---> F[Ordinais<br>p.ex. grau de dor<br>ligeira/moderada/<br>grave]
C ---> G[Discretos<br>p.ex. número de filhos]
C ---> H[Contínuos<br>p.ex. altura, pressão arterial]
style E color:#980000, stroke:#333,stroke-width:4px
style F color:#980000, stroke:#333,stroke-width:4px
style G color:#980000, stroke:#333,stroke-width:4px
style H color:#980000, stroke:#333,stroke-width:4px
Dados categóricos
A. Dados Nominais
Os dados nominais são dados não numéricos e que não têm qualquer ordem. Apenas é possível contá-los. Podem ser binários se existirem apenas duas categorias (por exemplo, vivo/morto; curado/não curado) ou podem assumir mais do que duas categorias (por exemplo, tipo sanguíneo A, B, AB, O; diabetes tipo I, tipo II ou gestacional; olhos castanhos, azuis ou verdes).
É possível representar categorias numericamente
Podemos representar vivo/morto como 1/0; ou ainda o tipo sanguíneo A/B/AB/O como 1/2/3/4, desde que saibamos o que cada número representa. Ao contrário dos dados numéricos, os números aqui apenas representam diferentes categorias e não têm qualquer significado matemático (não faria qualquer sentido somar ou fazer a média dos tipos sanguíneos…).
Β. Dados Ordinais
Quando as categorias podem ser ordenadas, os dados classificam-se como ordinais. Por exemplo, os doentes podem classificar a sua dor em ligeira, moderada ou grave. Neste caso, existe uma ordem natural dos valores, uma vez que a dor moderada é mais intensa do que a ligeira e menos intensa do que a grave.
Simplificar categorias leva à perda de informação
Os dados ordinais são, por vezes, transformados em dados binários para simplificar a análise, apresentação e interpretação de resultados (por exemplo, a classificação de dor pode ser simplificada em “grave” vs. “não grave”, esta última incluindo a dor ligeira e moderada). Isto leva sempre a perda de informação.
Dados numéricos
A. Dados Discretos
Os dados discretos apenas podem tomar um número finito de valores (normalmente valores inteiros); por exemplo, o número de crianças numa família. São frequentemente contagens, como o número de mortes num hospital durante um ano, o número de consultas de medicina geral e familiar durante um ano, ou o número de episódios epiléticos durante um mês.
Dados Discretos vs. Contínuos
Na prática, os dados discretos são muitas vezes tratados como contínuos quando o número possível de valores é relativamente grande.
Β. Dados Contínuos
Os dados contínuos são números (geralmente com unidades) que podem tomar qualquer valor dentro de um determinado âmbito. Alguns exemplos são a altura, a pressão arterial, a temperatura ou a glicemia. Na prática, o valor que tomam depende do grau de precisão do instrumento de medição (embora a altura, enquanto variável contínua, possa assumir qualquer valor, dificilmente conseguiremos distingur um paciente que meça 1,7000000 m de um outro paciente que meça 1,7000001 m - ambos seriam classificados como 1,70 m).
A categorização de dados contínuos leva a perda de informação
As variáveis contínuas podem frequentemente ser convertidas em variáveis categóricas. Por exemplo, o índice de massa corporal (IMC) é uma variável contínua que pode ser convertida numa variável categórica ordinal com quatro categorias: subpeso, normal, sobrepeso, e obesidade. Isto leva a perda de informação.